New York Times is back on the race science beat
New York Times is back on the race science beat
A kinda boring article though
|
|
|
|||||||||||||||
Back on the 23rd October 2025, some journalist I hadn’t heard of called Mike McIntire emailed me. He said he was writing some smear piece for the New York Times, and his email checked out. I mean, of course, he didn’t put it that way, but it was clear from his email what the intention was. Naturally, he asked to have some call or send some questions. The reason journalists do this is that their ‘professional ethics’ codes usually require it (sometimes local laws may also do so), and the secondary reason is that they can then engage in some fresh quote mining of whatever you say. So if you talk freely with such a journalist for an hour or so, then at some point you might have said something that sounded fishy taken by itself, but which in context made sense. However, it will soon appear in the smear piece without that context. Or better, it will appear with a rather different context that is provided by the journalist and probably be some adversary or another.
Mike McIntire is not a science journalist, so he is off his typical topic. This begs the question of why he was assigned to do this particular piece. I don’t know, but I can guess. My guess is that the piece was ordered by some editor or other higher-up. As a matter of fact, his email was timed with another very similar email around the same time from another journalist from another major American newspaper, Zusha Elinson from WSJ. Never heard of him either, but he emailed only a day later (24th October) and about the exact same topic. They both wanted to write some piece on Bryan Pesta’s academic freedom lawsuit. For those not familiar, Pesta was fired through tenure from his university ostensibly on grounds on data mishandling, but really for collaborating with us on doing anti-woke race and genetics research. The curious thing was the timing, only 1 day apart, and on an obscure lawsuit by a professor against a mediocre university. As far as I know, there were no legal updates on the case at the time, so why did 2 supposedly independent journalists both want to write a story before any legal updates? My guess is that they had insider knowledge of the verdict, which is why they were planning their smear pieces ahead of time and at two different outlets for extra publicity. Perhaps they were coordinating behind the scenes. I don’t really know, and any particular theory of this is of course a kind of conspiracy theory. Maybe one day we will know what the truth is.
Pesta’s lawsuit eventually concluded some time later (no money for poor Bryan), but no pieces by Mike McIntire or Zusha Elinson appeared. After a while, I started to think they had dropped the idea since apparently no one except Pesta replied to them. Today this was shown to be not correct, as New York Times dropped their new article:
If you read the piece you may get the impression that it’s a bit a nothingburger. I agree. Essentially nothing is new in it and it seems strangely delayed. It did however help provoke some debate on X/Twitter. There’s even a current AI news summary about it. It’s almost entirely negative about the NYT’s article. If you are too lazy to read the article, it goes like this:
- Fringe researchers (that’s us!) used some federally funded data for analyses that the NYT disapproves of.
- They duly bring in some carefully chosen critics to say some bad words about the work and or us. In this case everybody’s favorite strawberry Antifa geneticist Kevin Bird (burn down the buildings!), and omnibus denialist Sasha Gusev.
- There’s some additional quotes from various officials from ABCD/PNC/NIH who feign astonishment, anger etc..
- Some calls for further data security and of course more mandatory training.
The most amusing part is the angling to America’s geopolitical enemies, since apparently one of the authors of some paper or another is Chinese. According to their current googling, he may even live in China. Actually, at the time of the study he did not live in China at all. Then there’s another guy who was a coauthor on one paper, who lives in Russia. They then go on some fear mongering about what might happen if Americas enemies have copies of sensitive genetic datasets. It’s a funny line of argument considering that the ABCD itself previously held a contest for Chinese researchers to predict intelligence from the brain data. As a matter of fact, these data are not very sensitive, which is why 1000s of researchers and their students worldwide have access to them. You can simply go to the websites of these datasets and look at their proud listing of research. The page for ABCD’s portal lists 100s of studies, many done by researchers entirely based in China. This is also true for the UK Biobank by the way. The reason there isn’t more security is that the data aren’t terribly useful for anything geopolitically sensitive. In fact, even if the data were public, the subjects would have relatively little to fear. Yeah, someone could maybe identify some of them using FBI-like methods of uploading all the data to some genealogy websites and finding their 2nd cousins, but then so what? All you will get from this is that someone called Joe Doe filled out some survey years ago. It’s already illegal to use this information for much of anything. Since 1000s of people already have access to this kind of data, and I’ve never heard of any abuse cases, probably it’s not terribly useful otherwise someone would have already abused it to make money somehow.
Criticism of the study itself I think there were only two attempts. The first and most funny is that they showed this modified table:
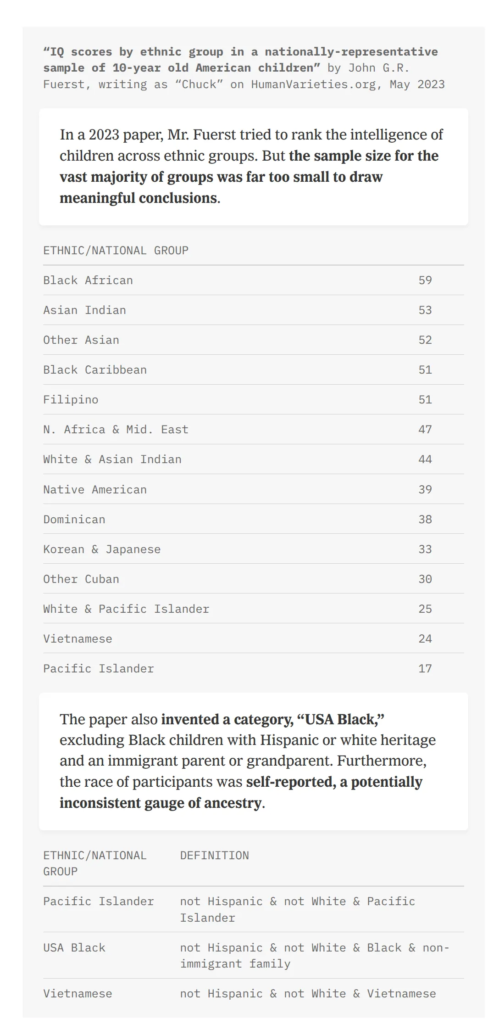
The goal was to show that some of the sample sizes were small and this is very bad. Of course, the total sample size of ABCD is 10k+, but if one keeps subsetting to minor ethnic groups, the samples may become small. Not really the fault of the researchers as such, just a data limitation. The fun thing is that they had chosen these sample sizes among many from a larger table, which I think may be this one (from HV blog):
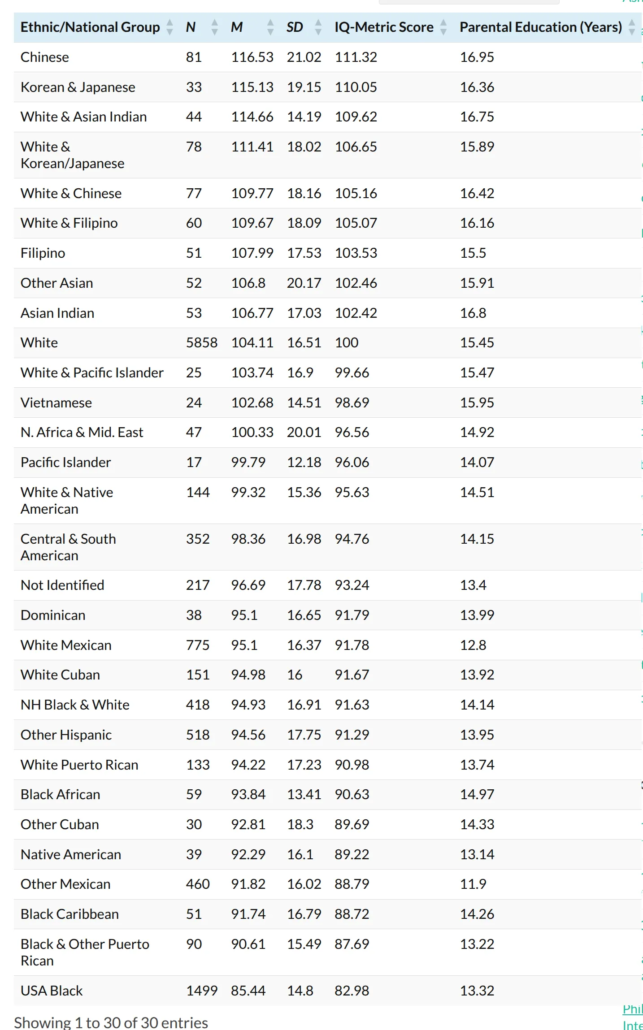
You can see that the larger sub-samples have all been left out to create the worst possible presentation. What a dumb trick. In any case, if one is estimating only the means of groups, and the gaps are large, then smallish samples can be OK. What matters is not so much the sample size, but the statistical power. That is, the precision of the studies relative to whatever effect is being studied. If you wanted to show that men and women differ in grip strength or height, you wouldn’t need many people since the gap is very large. Even 10 people from each group would be enough. In any case, what matters is the bigger picture, not the specific mean IQ of, say, Vietnamese Americans. There is a neat way to compare the precision of these estimates, namely, by comparing them with the same-ish groups on another test, the SAT/ACT. Doing so gives you this plot:
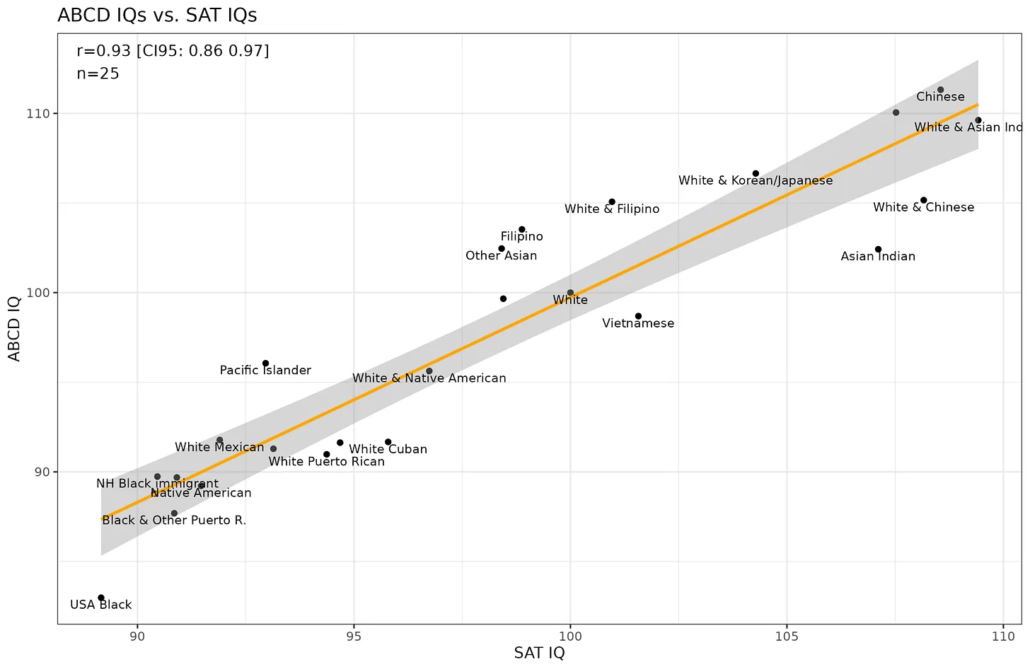
The IQ mean estimates are ‘only’ correlated at 0.93. Maybe there is some differences in the sampling (SAT takers are a different age cohort), but a small deviation from a correlation of 1.00 is expected due to the sampling error, and of course because the tests aren’t measuring entirely the same thing (SAT/ACTs are heavily loaded on knowledge, whereas ABCD’s battery includes a lot of memory tests). Rather, given that some of the samples are rather small, it is slightly surprising that they are so strongly correlated. It’s possible to adjust for the sampling error downwards bias (towards 0) in theory. If the amount of random error is known (standard errors of the mean) for each mean, one can estimate backwards and figure out what the original correlation most likely was before some random errors were added to the observations. The effect of the correction is probably small since we are already close to 1.00. I asked GPT to cook up some R code. After several false attempts, it got me some working code using variant of Deming regression I hadn’t heard of (based on York et al 2004). This approach produced the value of 0.965, which seems plausible enough. I would have to do some more simulations to be confident about this (topic for future post no doubt). The ones I did showed that the adjustment was working a little bit. Anyway, it is obvious that the small samples of some of the ethnics wasn’t important for the study.
The other criticism was just that the blank slate model was not assumed. Basically, the dog meme. One should control every possible alternative cause, according to NYT science, and not worry about the sociologist’s fallacy. Maybe they can take a lesson in causal reasoning since controlling for these factors gives uninterpretable results. Hereditarians and egalitarians agree that if we compare only (hypothetical) perfectly average specimens of this or that race group (in every way, their mothers and fathers income, education, occupational status, where they live, where they grew up, what job they have, their grandparents’ education etc.) then the gap would be smaller to some degree. Egalitarians like to think of this as some big a-ha! moment. However, on the hereditarian model this result is also expected because if you do such a statistical comparison, you are controlling for all the other things also indirectly caused by genetics (including in past generations by the ancestors’ genetics), and thus ending up with a comparison of a rather genetically elite hypothetical member of [ethnic group] compared with the average Joe Whiteman (or in the case of higher scoring ethnics, a below average member). This method cannot yield any causally informative conclusions, which is why it isn’t helpful to do this in endless detail as they propose (this useless method was also used in The Bell Curve replies). In fact, they spend a lot of space mentioning that the datasets didn’t even include all the possible hypothetical variables they could imagine being important, so naturally Pesta et al could not have used them to begin with, so how can they be faulted for not doing so?
The rest of the article was somewhat boring, and I don’t think it’s worth your time to dig up the various quotes they took from this or that blogpost and put in some other context. But I will give one example. They have this paragraph:
Another paper, coauthored by Mr. Kirkegaard, was limited by what he acknowledged were small sample sizes and a lack of nongenetic data. Those shortcomings did not stop him from trumpeting the findings online as proof that “genetic ancestry, not social race, explains observed gaps in social status.”
It concerns my 2023 blogpost about a paper based on ABCD data. They don’t seem to understand the point of the post. The point is simple: if social race (egalitarians claim, variously, that it’s not genetic, or it’s complicated, or whatever the current obfuscation of the month is) is so important causally for all sorts of things, then clearly, social race should predict outcomes better than genetic ancestry. This prediction has been tested a number of times in various datasets and using different methods. But it is always found that genetic ancestry (real race) predicts outcomes better than whatever race people consider themselves to be (or their parents or interviewers consider them to be). This is not consistent with their causal models that posit strong effects of social race. That’s why my quote says social race is not the causal factor at hand. They can then claim it is some other so far unidentified unmeasured causal factor (X), but then they gotta step up their science game and tell us what specifically it is. For decades, 100s of academics have been claiming it is discrimination based on skin color. But we and others have found that skin color does not predict outcomes when genetic ancestry is controlled so that causal model is clearly incorrect. The onus is on these egalitarians to produce anything resembling a coherent scientific theory of how gaps are caused, and how it can be tested. They have spent 10 decades making either too-vague-to-test claims, or advocating clearly disproven models (e.g. colorism, stereotype threat). It’s time to put up or shut up.




All humans are biologically identical in all respects. What could (not) be more obvious?